The Runbook Habit: How to Make Engineers Document While They Fix

It's 2am. The same engineer who fixed this exact problem six weeks ago is fixing it again. He doesn't remember the fix. He's re-Googling the same Stack Overflow answer, re-running the same three commands, re-discovering that the queue worker needs a restart in a specific order. The knowledge was in his head for about four hours after the last incident. Then it evaporated.
This is the most expensive habit in early-stage engineering, and almost nobody measures it.
I've built support and SRE functions from nothing. The single highest-leverage thing I did in the first few months was not buying a fancy observability tool or hiring a dedicated on-call team. It was getting engineers to write down what they just figured out, in the moment, before the adrenaline wore off. That's it. A runbook habit.
Most documentation efforts fail. I'll be honest about why. This one is different because it stops pretending documentation is a separate activity. It isn't. It's the last step of fixing.
Why most documentation dies
Let me be blunt about the usual failure mode, because if you don't understand it you'll repeat it.
You announce a documentation initiative. Maybe there's a Confluence space. Someone makes a beautiful template with twelve sections. There's a Friday "docs day." For two weeks people are enthusiastic. Then a deadline hits, docs day gets skipped, the wiki goes stale, and within a quarter the documentation is worse than useless—it's actively misleading, because half of it is wrong and nobody knows which half.
Here's the root cause. Documentation written as a separate task always loses to real work. Always. It's a chore with no immediate payoff, scheduled against shipping features that have deadlines and stakeholders. You cannot win that fight with process. I've watched smart teams try, and the docs lose every time.
The second failure is scope. People try to document the system. The architecture, the data model, the deployment topology. That kind of documentation is enormous, goes stale the moment someone ships, and nobody reads it at 2am anyway. At 2am you don't want a system overview. You want to know how to make the alert stop.
So forget documenting the system. Document the failures.
What a runbook actually is
A runbook is not a design doc. It's not an architecture overview. It's a recipe for one specific thing going wrong and what to do about it.
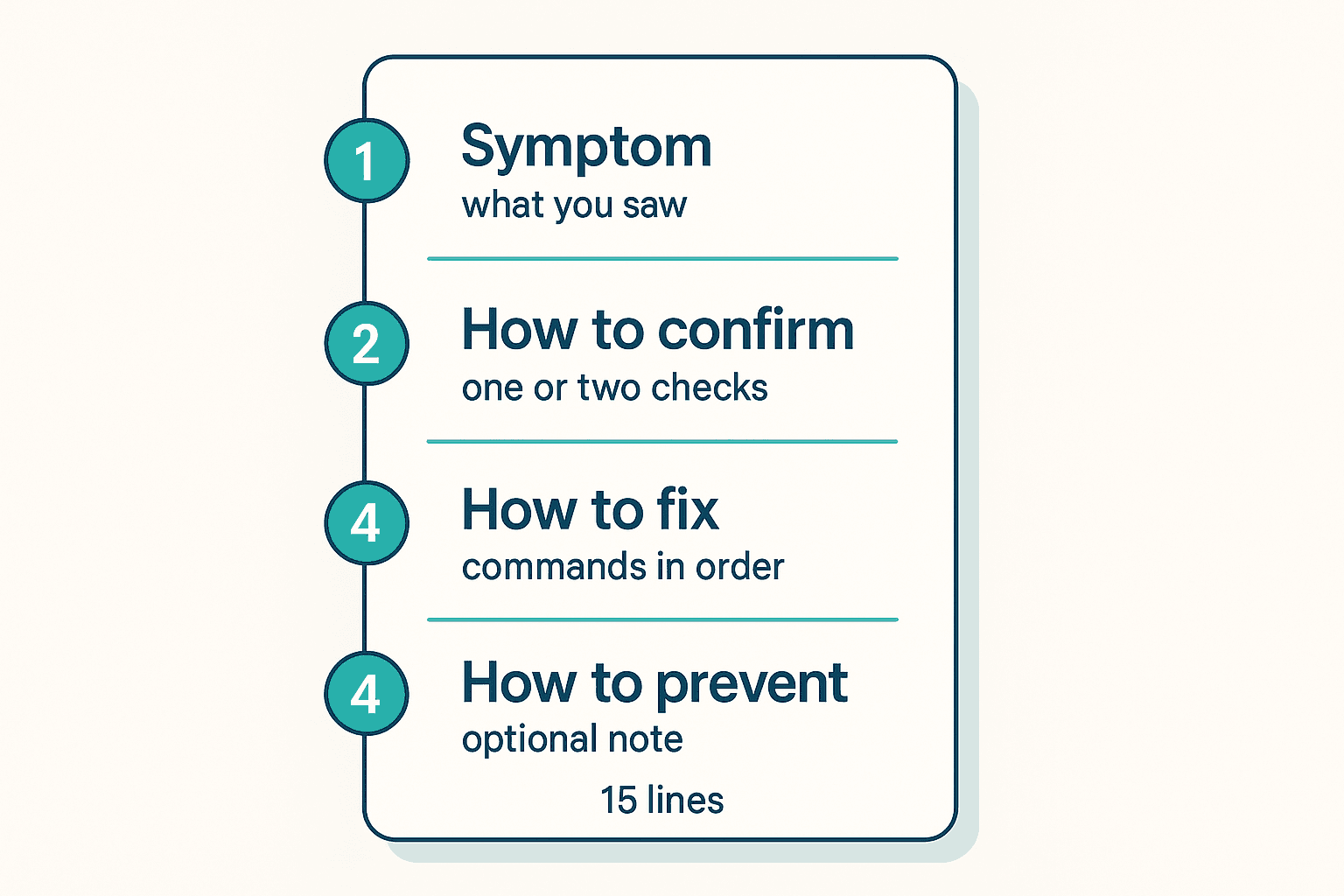
The whole template is four sections. I've tried longer ones. They don't get filled in.
- Symptom — what you actually saw. The alert text, the error message, the customer complaint. The thing someone will paste into search when it happens again.
- How to confirm — the one or two checks that prove this is really the problem and not something that looks like it. "Check the dead-letter queue depth." "Grep the logs for
connection reset." - How to fix — the actual steps. Commands, in order. The dashboard to open. The toggle to flip. Concrete enough that a tired engineer at 2am can follow it without thinking.
- How to prevent — optional, often blank at first, and that's fine. This is where you note "this keeps happening because X" so that future-you has a paper trail when you finally decide to fix the root cause.
That's the entire thing. Four headings. A good runbook is often fifteen lines. If it's a page long, you've written a design doc by accident.
The key insight is in the Symptom section. Write it the way it will be searched for, not the way you'd describe it in a meeting. If the alert says 5xx rate above threshold on checkout, the runbook title should contain those words, not "Intermittent payment availability degradation." Future-you is going to Cmd-F for the literal alert text. Make it findable.
The rule that makes it stick
Here is the one rule. Print it. Put it in your on-call onboarding.
If you Googled it, write it down.
That's the whole habit. If you had to leave your own codebase to figure something out—searched Stack Overflow, read a vendor's docs, asked an LLM, dug through a GitHub issue from 2021—that is the signal. It means the knowledge wasn't in your system, and you just paid the cost of acquiring it. Don't throw that away. Capture it while it's hot.
I like this rule because it's self-selecting. It doesn't ask people to document everything, which is the trap. It asks them to document the specific things that were hard to find—which, almost by definition, are the things worth a runbook. The trivial stuff you knew off the top of your head doesn't need writing down. The thing that cost you forty minutes of searching at 2am absolutely does.
The corollary: if a runbook already existed and you used it, and it was wrong or incomplete, fix it on the spot. A runbook you just followed is the easiest one to improve, because you've just tested every line against reality. Two minutes of editing now saves the next person an incident.
Where runbooks live
This matters more than people think, and getting it wrong quietly kills the habit.
Runbooks must live where the work happens, not in a separate documentation product nobody opens. For most teams that means in the repo, as plain markdown, in a runbooks/ directory next to the code. Version controlled. Reviewed in the same pull requests as the code. Searchable with the same tools the engineers already use all day.
Why in the repo and not the wiki? Three reasons.
First, proximity. If the runbook is a file in the repo, it shows up when you grep. It's two keystrokes away from the code that broke. A wiki is a context switch—a different tab, a different search box, a different mental mode. Friction kills habits.
Second, review. When a runbook lives in a PR, your teammates see it. They catch the wrong command before it bites someone at 2am. Wiki edits happen in the dark and nobody reviews them.
Third, it stays alive with the code. When someone refactors the thing a runbook describes, the runbook is right there in the diff. They're far more likely to update it—or at least notice it's now wrong—than if it's hidden in a separate system they forgot exists.
The one connection you must build: from the alert to the runbook. When an alert fires, the notification should link directly to the relevant runbook. Most alerting tools let you attach a runbook URL to an alert definition. Do it. The moment of maximum motivation to read a runbook is the moment the alert fires, and the moment of maximum motivation to write one is right after you've resolved it. Wire both into the alert.
Tie it to the incident flow, or it won't happen
This is the part that separates a runbook habit that lasts from another dead wiki.
Writing the runbook has to be a step in resolving the incident, not a separate task you hope someone does later. "Later" never comes. The incident closes, the person sleeps, and by morning it's gone.
So bake it into your on-call flow. Here's roughly what mine looks like.
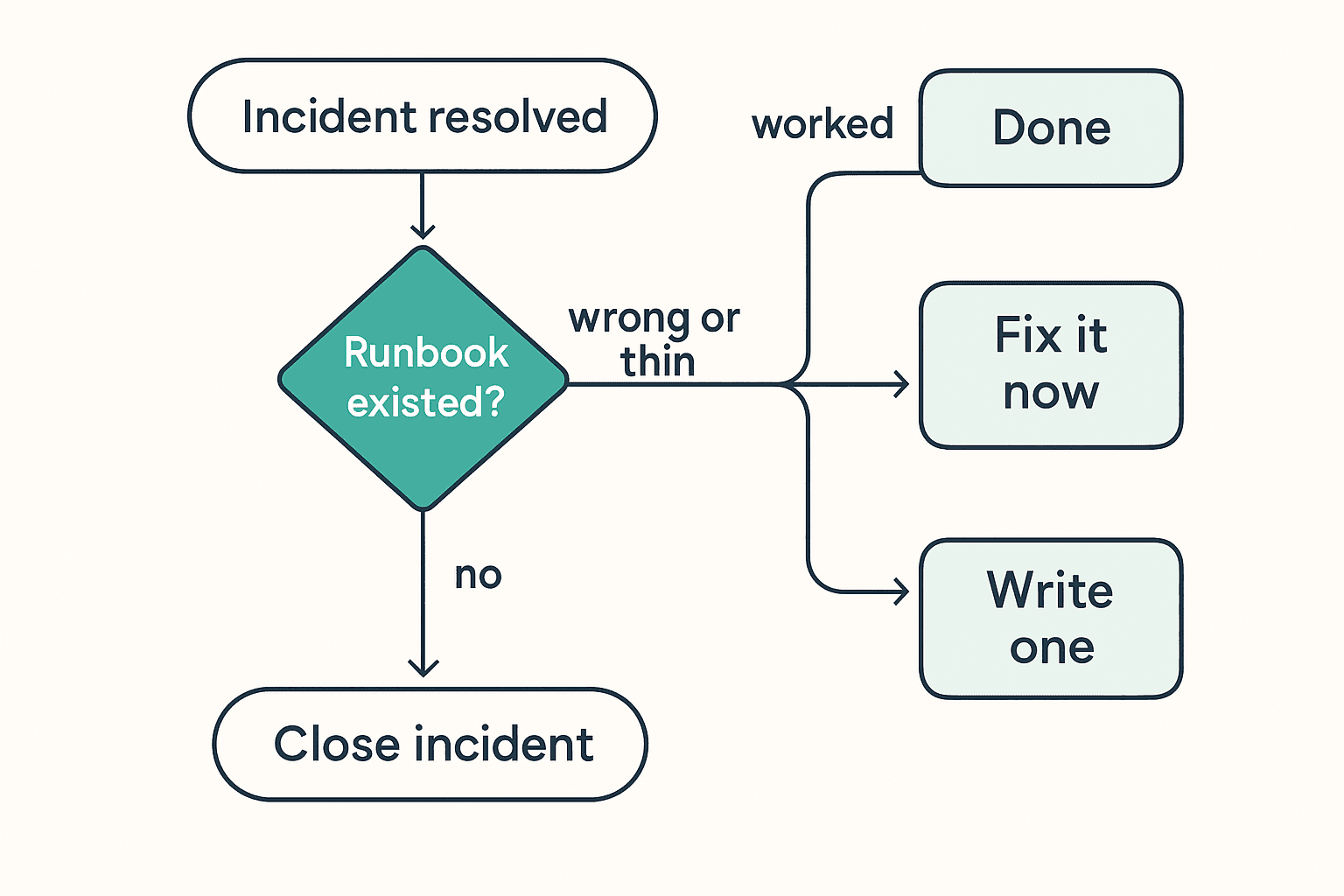
When an incident is resolved, before it can be marked closed, the on-call engineer answers one question: did a runbook for this exist?
- If yes and it worked — done. Maybe a one-line tweak.
- If yes but it was wrong or thin — fix it now, in the same five minutes. You have the freshest possible context.
- If no — write one. Four sections. Fifteen lines. The symptom you saw, how you confirmed it, what you did, and a note on prevention if you have one.
The runbook gets written or updated as part of closing the incident. It is not a follow-up ticket. It is not a backlog item. It is the last thing you do before you go back to bed. A ten-minute task while the memory is vivid, not a forty-minute archaeology project three weeks later when you've forgotten the details.
For real incidents that get a post-mortem, the runbook update is an explicit line item in the template. No post-mortem is complete until the runbook exists. That's not bureaucracy—it's the single most useful output of the whole exercise. The five-whys analysis is nice. The runbook is what actually saves the next person.
If you run blameless post-mortems—and you should—the runbook is also where the "blameless" part earns its keep. The point of capturing the fix isn't "Dave should have known this." It's "the system didn't know this, now it does." That framing makes people write more honestly, because they're documenting a gap in the system, not confessing a personal failure.
Keeping it honest over time
A few things I've learned about keeping this alive past the first enthusiastic month.
Don't review runbooks on a schedule. Quarterly "runbook review" meetings are theatre. Runbooks get validated naturally—every time someone uses one in an incident, that's a real-world test. The on-call rotation is your review process. If a runbook is wrong, the next incident exposes it, and the rule says you fix it then.
Accept that some runbooks will rot, and that's okay. If a class of failure stops happening because you actually fixed the root cause, its runbook becomes obsolete. Fine. A dead runbook for a dead problem isn't a liability the way a dead design doc is. Worst case, someone reads it, finds it doesn't apply, and deletes it.
Don't let it become a gate that blocks recovery. The runbook gets written after the fire is out, never during. Nobody documents while customers are down. The habit lives in the cooldown, in the calm ten minutes after resolution. If you ever feel tempted to make documentation block the fix, you've misunderstood the whole thing.
Lead by doing it yourself. The first ten runbooks should be written by whoever is most senior, in the moment, visibly. If the founder or staff engineer writes runbooks after their own 2am fixes, everyone else does too. If they don't, no policy will save you.
The bottom line
You don't need a documentation strategy. You need a habit, and the habit is small: if you Googled it, write it down—four sections, in the repo, before you close the incident.
The reason this works when grand initiatives fail is that it never asks anyone to do documentation as a separate job. It asks them to spend ten extra minutes finishing the job they were already doing—turning a fix they just made into a fix the next person doesn't have to make.
Do this for six months and something quiet but enormous changes. The same problem stops costing you a full incident every time. On-call gets less frightening because the scary unknowns become fifteen-line recipes. New engineers onboard faster, because the painful institutional knowledge is finally written down instead of trapped in three people's heads.
The knowledge stops evaporating. That's the entire game.
Hit like if you enjoyed this post!
Keep reading
Error Budgets Are a Management Tool, Not an Engineering One
Most error budgets die quietly because engineers introduced them with no authority behind them. The number only matters when it changes what leadership does. Here is how to wire budget burn into roadmap decisions, exec reviews, and feature-freeze conversations so it actually has teeth.
June 09, 2026Support & SRESRE Org Design: Centralized, Embedded, or Platform?
Centralized, embedded, or platform SRE? Each model solves a different problem and breaks in a different way. Here is how to pick one, and how to migrate when you outgrow it.
June 05, 2026