L1/L2/L3 Doesn't Exist at a Startup — But the Work Does

Someone asks how your support is structured. You say "L1/L2/L3" because that's the language everyone uses. Then you look around the room and realise there are eight of you, and three of those people are engineers who also build the product, and the "support team" is whoever happens to see the message in the shared inbox first.
So no. You don't have tiers. You have eight people and a lot of work.
Here's the trap I see early-stage teams fall into. They read about how the grown-ups do support — first line, second line, third line, escalation paths, runbooks, SLAs — and they try to build a miniature version of it. They appoint someone "L1". They draw an escalation diagram. They feel organised. And it's all cosplay, because the volume doesn't justify any of it and the structure just adds friction to a team that should be moving fast.
But here's the part people miss when they overcorrect and throw the whole model out: the tiers are fake, the work is real. First response, investigation, deep fixes — that work exists the moment you have a single customer. It doesn't need a tier. It needs an owner.
The work, not the org chart
Forget L1/L2/L3 as job titles. Look at what the labels actually describe. They're three kinds of work that happen to a support ticket.
First response. Someone says hello, you say hello back. You acknowledge the problem, you ask the obvious clarifying questions, you check whether it's a known issue. Most of this is communication and triage, not engineering. A huge share of "tickets" die here because the answer is "you're looking in the wrong menu" or "that's expected behaviour."
Investigation. The problem is real and not obvious. Someone has to reproduce it, read the logs, check the database, work out whether it's a bug, a config issue, a data issue, or the customer doing something you never anticipated. This is the work that eats your day, because it's open-ended and you don't know how deep it goes until you're in it.
Deep fixes. It's a real bug or a real gap in the system. Now it needs a code change, a migration, a config rollout — something that touches the product and carries risk. This is engineering work that happens to have been triggered by a support ticket.
At a big company these three things become three groups of people because the volume is enormous and specialisation pays off. At eight people, the same one or two humans do all three in a single afternoon, often on the same ticket. That's fine. That's correct, actually. The mistake is pretending the work doesn't change shape just because the same person does all of it.
Who handles what when there are only eight of you
Here's roughly how I set this up on a small team, and it's deliberately boring.

Put one person on the front line each day. Not a dedicated support hire — you don't have one and you don't need one yet. A rotation. Whoever is on support duty that day owns first response. They watch the inbox, they answer the easy stuff, they triage everything else. This is the single most valuable move you can make early, and it costs you nothing but a calendar.
The reason is simple. If support is "everyone's job," it's nobody's job. Messages sit for three hours because each engineer assumes another one saw it. With a named person per day, there's always exactly one throat to choke and one person who can context-switch on purpose instead of everyone context-switching by accident. Your other engineers get to keep their heads down and build, which is the entire point of being small and fast.
The support-duty person handles first response and the shallow end of investigation. When something turns out to be a real bug — a deep fix — it goes to whoever owns that part of the codebase, scheduled like any other engineering work. Not dropped on them at random. Interrupt-driven engineering is how you destroy a small team's velocity, and the rotation exists specifically to absorb the interruptions so the rest of the team doesn't have to.
You'll be tempted to skip the rotation because eight people feels small enough to just wing it. Don't. The rotation is the cheapest structure you will ever buy, and it's the thing you'll wish you'd had the first time a customer issue sat unanswered over a weekend.
The founder problem
One warning, because I've watched it happen more than once. On tiny teams the most senior engineer or the technical founder ends up doing every deep fix and most of the hard investigation, because they're the one who knows where the bodies are buried. That feels efficient. It is a debt you're taking on, not a strength.
Every ticket that only one person can resolve is a ticket you can't delegate later. Use the support rotation to spread that knowledge deliberately. When the duty person hits something they can't investigate, pair on it rather than handing it off. It's slower today and it's the only thing that buys you a team that can scale tomorrow.
Track the work now so you can split it later
This is the part almost nobody does early, and it's the part that pays off the most. Tag every ticket with the kind of work it actually required. Not the customer's category. The internal shape of the work.
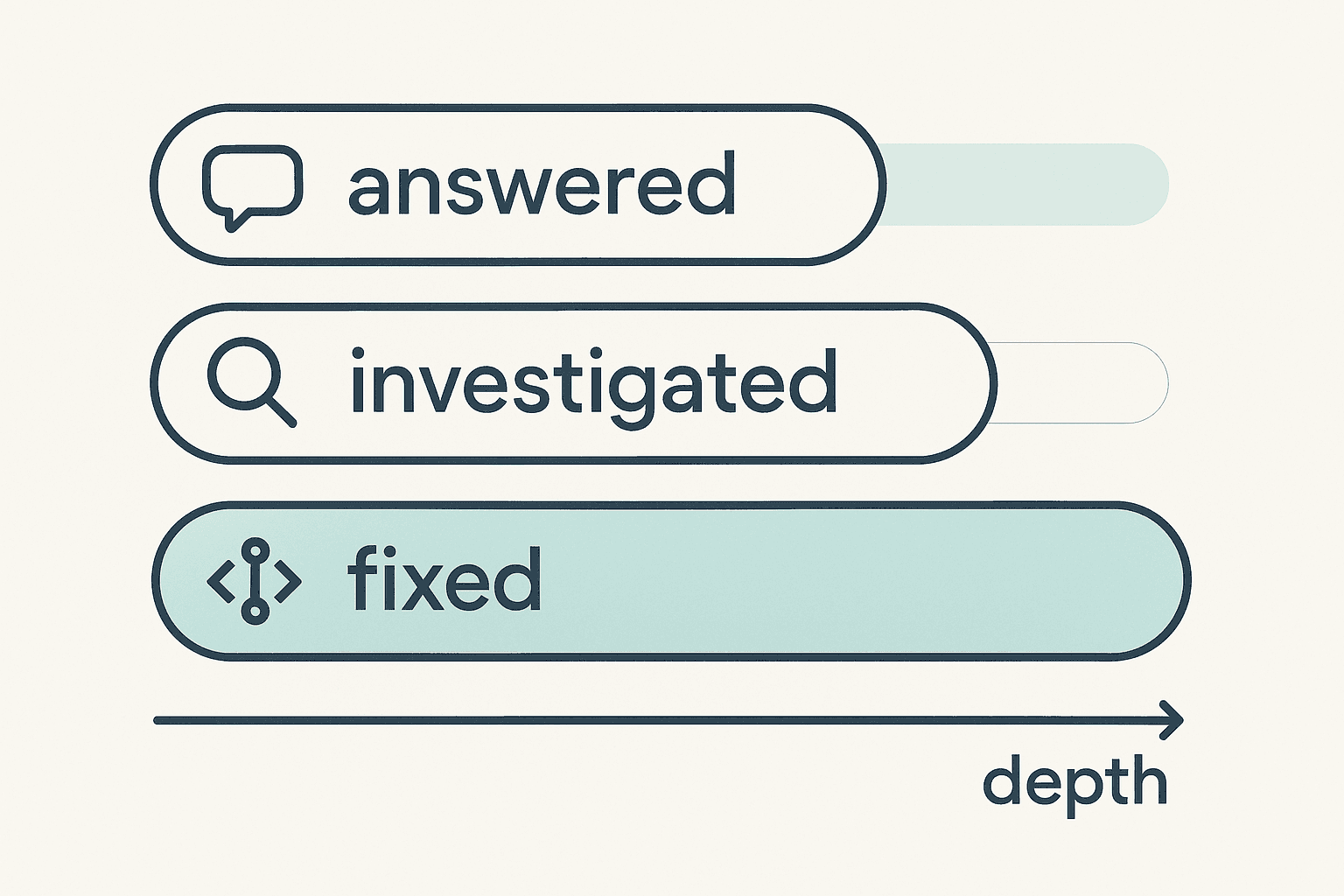
You don't need a tool for this. You need a few labels in whatever you already use — a shared inbox, Linear, a spreadsheet, Slack with emoji reactions, genuinely anything. Here's the lightweight scheme I'd adopt on day one.
Tag each resolved ticket with the depth it reached:
- answered — resolved at first response. No investigation needed. (This is your old "L1".)
- investigated — required digging, but the fix was operational: a config change, a manual data correction, a re-explanation, a workaround. No product code shipped. (Your old "L2".)
- fixed — required a code change, migration, or deploy to resolve. (Your old "L3".)
Then add a second, smaller tag for the area: billing, auth, data import, performance, whatever your real buckets are. Two or three labels per ticket, takes five seconds, done.
That's it. That's the whole scheme. The discipline isn't the tooling, it's tagging consistently every single time, including the boring ones.
Why this is worth the five seconds
Because in six or twelve months, when someone asks "should we hire a support person?" or "do we need an SRE?", you will have an actual answer instead of a vibe.
If 70% of your tickets are tagged answered, you have a documentation and onboarding problem, and your next hire is a support or success person, not an engineer. If a third of your tickets are fixed, your product has real quality gaps and the work is genuinely engineering — hiring a junior support agent won't touch it. If everything is clustering in billing and investigated, you know exactly where to spend the next month hardening the system.
And when you finally do grow past the point where a rotation works, the split writes itself. A real first-line role is "owns the answered tickets and the front of investigated." A real second-line role is "owns deep investigated and triages into engineering." The boundary between teams is just the boundary in your data that you've been recording all along. You're not designing tiers from a blog post. You're drawing lines through evidence you collected from your own customers.
I've sat in the meeting where a team tries to design their support org with no data, arguing from gut feel about where the volume is. It's a waste of a week and the answer is usually wrong. The team that tagged tickets for a year walks into that same meeting and finishes it in an hour.
Why premature tiers are a trap
Let me be blunt about the failure mode, because the instinct to look organised is strong and it costs real money.
When you build a tiered structure before you have the volume, you get all of the overhead and none of the benefit. You get handoffs between "tiers" that are the same two people, so a ticket bounces around an escalation path for show before landing on the person who was always going to fix it. You get an "L1" who isn't allowed to touch the real problem and an "L3" who's annoyed at being interrupted, and the customer waits while the ceremony plays out.
Worse, you start hiring against the fake structure. You hire a dedicated "L1 agent" because the org chart has a box for one, and now you've spent a salary on someone who can only handle the answered tickets — except at your stage most of your real pain is in investigated and fixed, which they can't help with. You've optimised for a shape you don't have yet.
Structure should lag reality, not lead it. Add a role when the work for that role exists in volume and is starving for an owner — not when a framework says a company your size "should" have one. The tagging scheme is what tells you when that moment actually arrives. Until then, the rotation plus three labels is more support process than most eight-person companies will ever need.
The one exception: don't let "we're too small for process" become an excuse for chaos. No process and a tracking habit is the goal. No process and no record is just losing information you'll desperately want later.
The bottom line
You don't have tiers. You have first response, investigation, and deep fixes, and at eight people the same few hands do all three. That's not a problem to fix — it's the right way to run at your size.
Do three things and you've covered it. Put one named person on the front line each day so support stops being everyone's-and-therefore-nobody's job. Schedule deep fixes as real engineering work instead of letting them shred your team's focus. And tag every ticket by the depth it reached — answered, investigated, fixed — so that the day you outgrow this, the org you build next is drawn from your own data instead of someone else's framework.
The tiers will come if you grow enough to need them. When they do, you'll split the work along lines you've already been recording, and it'll feel obvious. That's the goal: not to look like a bigger company today, but to make sure that when you become one, the seams are already in the right place.
Hit like if you enjoyed this post!
Keep reading
Error Budgets Are a Management Tool, Not an Engineering One
Most error budgets die quietly because engineers introduced them with no authority behind them. The number only matters when it changes what leadership does. Here is how to wire budget burn into roadmap decisions, exec reviews, and feature-freeze conversations so it actually has teeth.
June 09, 2026Support & SRESRE Org Design: Centralized, Embedded, or Platform?
Centralized, embedded, or platform SRE? Each model solves a different problem and breaks in a different way. Here is how to pick one, and how to migrate when you outgrow it.
June 05, 2026