Building L1 That Resolves, Not Just Escalates

The first time I built a support function from scratch, I made a mistake I see almost everywhere now. I hired L1, gave them a ticketing tool, wrote a one-page escalation policy, and called it done. Within a month I had a team of very polite people whose entire job had become deciding which engineer to bother.
That is the failure mode. L1 becomes a forwarding service. A ticket comes in, L1 reads it, L1 can't act on it, L1 escalates. Now the customer has waited longer than if they'd reached an engineer directly, the engineer is annoyed at the interruption, and L1 feels like a call centre that exists to apologise. Everyone loses, and the metrics often look fine while it's happening.
A real first line resolves things. Not everything — that's not the point — but a meaningful share of what comes in, on its own, without waking anyone up. The difference between those two outcomes is not the calibre of the people you hire. It's the tooling, the runbooks, and above all the incentives you wrap around them.
This is the part of scaling support that nobody warns you about, because the org chart looks identical either way. You have an L1 tier on paper. Whether it adds value or just adds a hop is decided by a hundred small choices that don't show up in the headcount plan.
Why L1 turns into a relay
L1 escalates by default for one of three reasons, and usually all three at once.
They can't see anything. If your first line can't read the logs, can't query the database, can't see the customer's account state, can't check whether the last deploy broke something — then escalating isn't laziness. It's the only move available. You've handed someone a phone and no eyes.
They don't know what to do. Even with visibility, a new agent facing "payments are failing for one customer" has no idea whether that's a known issue, a config problem, or a genuine incident. Without a written path, the safe choice is always to escalate. Nobody got fired for forwarding a ticket to engineering.
Escalating is rewarded, resolving is punished. This is the one people miss. If your agents are measured on tickets closed per hour, escalating is fast and resolving is slow. If they get yelled at when they touch production and try something that doesn't work, they learn to never touch production. The incentives quietly train them to be a relay, and then everyone blames the people.
Fix the first two and you've made resolution possible. Fix the third and you make it the obvious choice. You need all three.
Give them eyes and hands
Resolution starts with access. An L1 agent who can only read the ticket is a translator, not a problem-solver.
The non-negotiable baseline, in my experience, is read access to everything and safe write access to a curated set of actions. Concretely:
- Logs and traces, scoped to what they need, searchable, with a sane retention window. Not "ask the on-call to grep for you."
- A read replica or an internal admin tool for customer and account state. They should be able to answer "what does this customer's account actually look like right now" in fifteen seconds.
- A small, deliberate set of safe write actions: resend a verification email, re-trigger a stuck webhook, clear a cache for one account, reset a session, requeue a failed job. Each one guarded, logged, and impossible to use to cause real damage.
- Visibility into recent deploys and current system status, so "did something just change" is a question they can answer themselves.
The art is in that fourth point. Most of what an L1 agent needs to do safely is a narrow list of reversible, single-customer actions. Build those into an internal tool with guardrails and you turn "escalate to engineering" into "click the button." I've watched resolution rates jump fifteen, twenty points just from building three or four of these.
The instinct to lock everything down is understandable and almost always overcorrected. Yes, give least privilege. But least privilege for a support role includes the privilege to actually support someone. A first line that can do nothing will escalate everything, and that costs you far more engineering time than the occasional mistake an empowered agent makes.
Runbooks are the product
If access is the hands, runbooks are the brain. And I mean real runbooks, not a wiki graveyard.
A good runbook answers a specific symptom: "customer reports they didn't receive their export email." It lists what to check, in order. It says what the common causes are and how to tell them apart. It gives the exact safe action to take for each cause. And it states the precise condition under which you stop and escalate — not "if you're unsure" but "if the job shows as completed but no email was sent, escalate to platform with the job ID."
The discipline that makes runbooks work is this: every escalation should produce or improve a runbook. When L1 escalates something they couldn't handle, an engineer resolves it, and the resolution gets written down as a path L1 can follow next time. Do this consistently and your escalation volume drops month over month on the same ticket types, because the second occurrence is now an L1 ticket.
This is also how you get real deflection. People talk about deflection as a help-centre problem — write good docs, customers self-serve, fewer tickets. That's true and worth doing. But the bigger lever is internal deflection: turning tomorrow's escalation into today's runbook so it never reaches an engineer again. The first line becomes a living record of every problem you've already solved.
Two warning signs your runbooks have rotted. First, agents stop opening them because they're out of date and they've learned not to trust them — at that point the runbooks are worse than useless, because they signal that documentation is theatre. Second, the same ticket type escalates over and over with no runbook ever appearing. That means escalation has no feedback loop, and you're paying the engineering tax on the same problem indefinitely.
The metrics trap
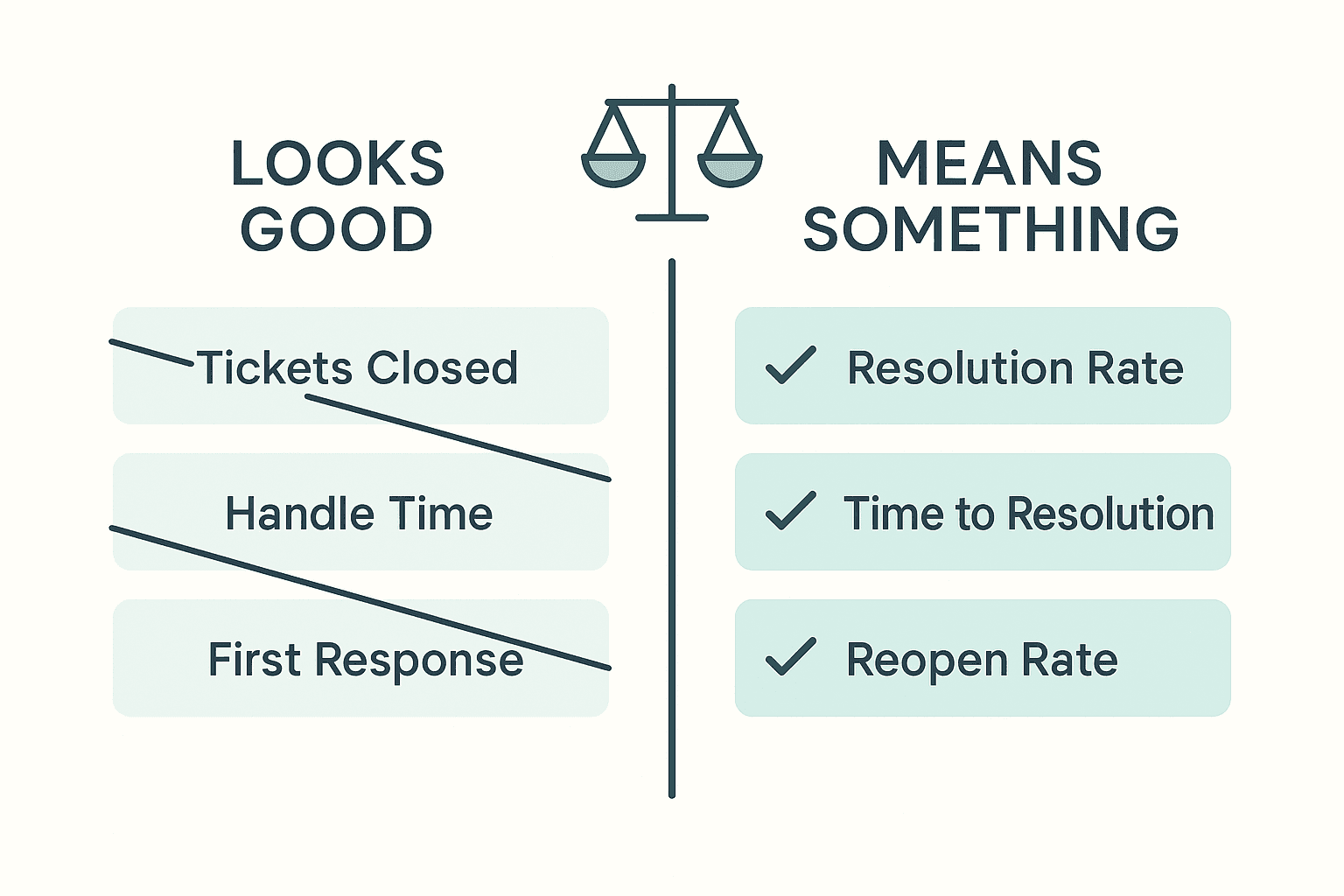
Here is where most support orgs quietly sabotage themselves. They measure what's easy to count instead of what they actually want, and the team optimises for exactly what you measure.
Let me be blunt about which numbers drive which behaviour.
Metrics that look good and rot the team
Tickets closed per agent. Raw close count rewards volume, and the fastest way to close a ticket is to escalate it or shove it back at the customer with a canned "have you tried logging out?" You will get high close counts and miserable customers. I've seen agents close-and-reopen the same ticket to pad numbers. The metric created the fraud.
Average handle time, on its own. AHT measured alone teaches agents to get off the conversation as fast as possible. That means premature closes, rushed answers, and escalating anything that looks like it'll take a while. The tickets that need the most care are exactly the ones AHT punishes you for handling well.
First response time, treated as the headline. Fast first response is good. But when it becomes the number leadership stares at, you get a fast meaningless first response — an autoreply with a human face — followed by silence. You optimised the easy part and ignored the hard part.
The common thread: each of these is a proxy that's easy to game, and a team under pressure will always game the proxy before they'll do the harder real work. Not because they're dishonest. Because that's what you told them mattered.
Metrics that actually mean something
L1 resolution rate. The share of tickets resolved at the first line without escalation. This is the number that tells you whether you've built a support function or a switchboard. Watch it as a trend, by ticket type, and you'll see exactly where your tooling and runbooks are working and where they aren't.
True time-to-resolution. Not time to first response. The time from "customer has a problem" to "customer's problem is gone." This is what the customer actually experiences, and it's the number that holds the whole system honest.
Reopen rate. The percentage of "resolved" tickets the customer comes back on. This is the antidote to every close-count game. If an agent closes fast but the customer returns, the reopen rate catches it and the fast close was a lie. I weight this heavily — a low close count with a low reopen rate beats a high close count with a high reopen rate every single time.
Customer satisfaction, tied to the specific interaction. Not a quarterly survey. A simple thumbs up or down on the actual ticket, attributed to the resolution. It's noisy per-ticket but honest in aggregate, and it's the only metric that captures whether the customer felt helped rather than processed.
If I could only watch two numbers, they'd be L1 resolution rate and reopen rate, side by side. Resolution rate without reopen rate rewards reckless closing. Reopen rate without resolution rate rewards escalating everything so you're never on the hook. Together they're hard to game, because the only way to win both is to actually solve the customer's problem and have it stay solved. That's the whole job.
Make resolving the win
Tooling and metrics set the stage. Culture decides what people actually do on it.
The single most important thing you can do is make resolution the celebrated outcome and escalation the neutral one. Not punished — you never want an agent sitting on something they can't handle because they're scared to escalate. Neutral. The agent who safely resolved a tricky ticket using a runbook and a couple of admin actions did the more valuable thing, and that should be visible. Share those wins. Name them.
Then close the loop on escalations so they teach instead of just removing work. When L1 escalates, the engineer who resolves it should send back a short explanation of what it was and how they fixed it. That does two things: the agent learns, and you've got the raw material for the next runbook. An escalation that vanishes into engineering and comes back as a silent "resolved" teaches nobody and guarantees the same ticket escalates again.
Give them time to learn. An L1 team run at a hundred percent utilisation will never improve, because improvement is the work that happens between tickets — reading the runbook that didn't exist last week, shadowing an engineer on an incident, writing down what they just figured out. Budget for it explicitly or it won't happen.
And hire for curiosity over politeness. Polite people who escalate are easy to find and a trap. The agent you want is the one who, faced with something unfamiliar, wants to understand it. You can teach the tools and the runbooks. You can't easily install the instinct to dig in rather than forward.
The bottom line
A first line that resolves doesn't happen by drawing an L1 box on the org chart. It happens because you gave people the access to see and act, the runbooks to know what to do, the metrics that reward solving over forwarding, and a culture where resolving is the win.
Get those four right and your engineers get their focus back, your customers get faster answers, and your support function stops being a tax and starts being a moat. Get them wrong and you've built an expensive relay that frustrates everyone and looks fine on a dashboard right up until your best customers leave.
The test is simple. Pull up your L1 resolution rate and your reopen rate, and watch them together over a few months. If resolution is climbing and reopens are flat or falling, you've built the real thing. If you can't even produce those two numbers, that's your first problem — and the most useful place to start.
Hit like if you enjoyed this post!
Keep reading
Error Budgets Are a Management Tool, Not an Engineering One
Most error budgets die quietly because engineers introduced them with no authority behind them. The number only matters when it changes what leadership does. Here is how to wire budget burn into roadmap decisions, exec reviews, and feature-freeze conversations so it actually has teeth.
June 09, 2026Support & SRESRE Org Design: Centralized, Embedded, or Platform?
Centralized, embedded, or platform SRE? Each model solves a different problem and breaks in a different way. Here is how to pick one, and how to migrate when you outgrow it.
June 05, 2026