Technical Debt: A CTO's Guide to Measurement, Prioritization & Reduction

Every engineering organization has technical debt. The ones that thrive are not the ones with the cleanest codebases — they are the ones that know exactly how much debt they carry, where it lives, and which slice of it is actively costing them money.
Most teams treat technical debt the way people treat clutter in a garage: vaguely uncomfortable, occasionally addressed in a guilty weekend sprint, never measured. That approach works until it doesn't. When debt finally bites, it bites in the middle of a launch, an audit, or a hiring push.
This guide is the playbook I use with engineering leaders to turn technical debt from a recurring source of anxiety into a managed line item — measured, prioritized, and actively reduced without grinding feature work to a halt.
What Technical Debt Actually Is (And What It Isn't)
Ward Cunningham coined the term in 1992. His original metaphor was financial: shipping imperfect code is like taking out a loan. You move faster now, but you owe interest in the form of slower future development until you "repay" it through refactoring.
Two things have been lost in translation since then.
First, not all shortcuts are debt. A pragmatic decision to defer a feature is not debt. A choice between two equally valid architectures is not debt. Debt is specifically the cost of choosing a solution you know is suboptimal because the right solution is too expensive right now.
Second, debt is not always bad. Strategic debt — taken consciously, tracked explicitly, and repaid on a known schedule — is one of the most powerful tools a CTO has. The problem is unconscious debt: the kind that accumulates while no one is looking.
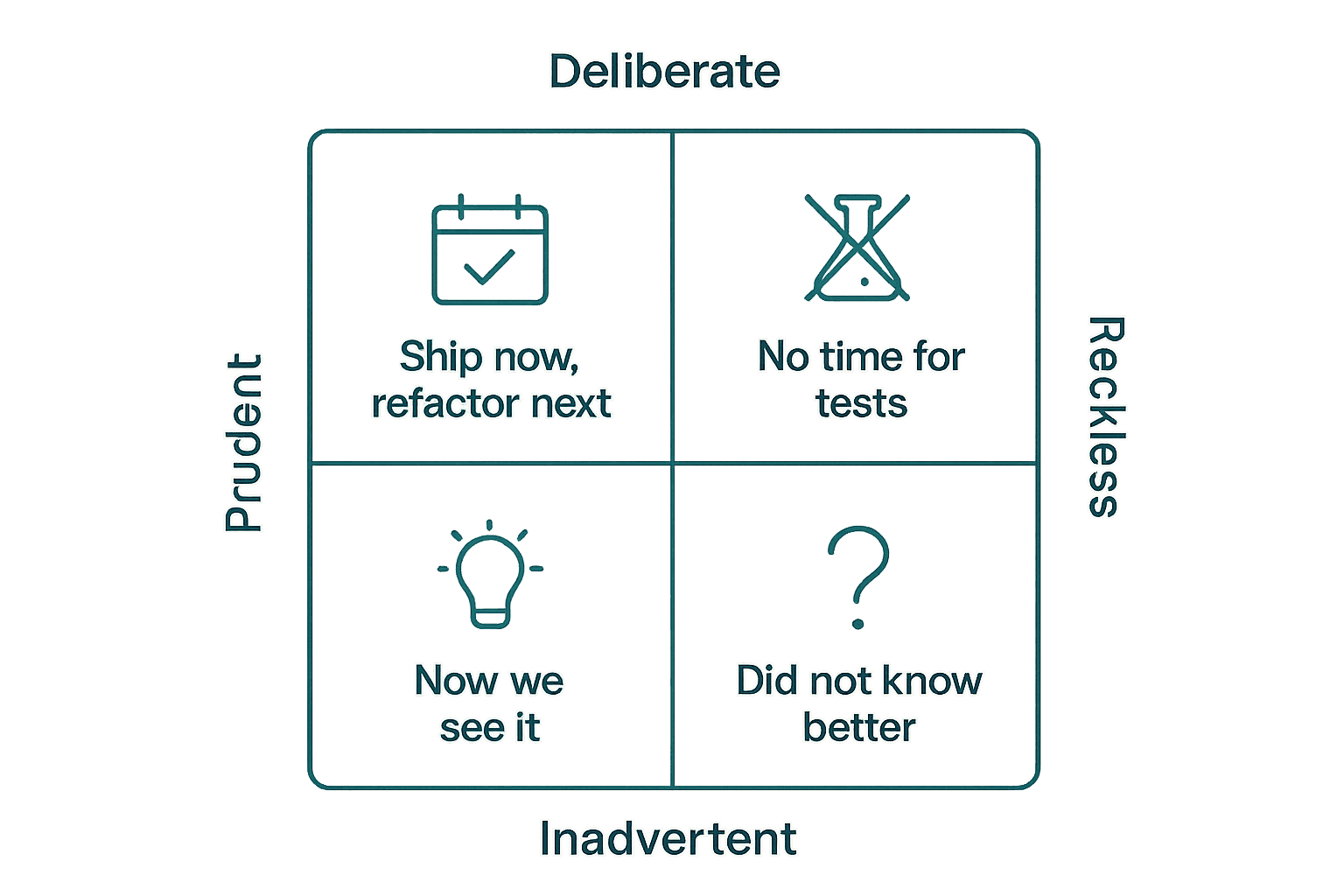
A useful classification, adapted from Martin Fowler's quadrant:
- Deliberate and prudent: "We must ship before the demo. We will refactor the auth layer next sprint."
- Deliberate and reckless: "We don't have time to write tests."
- Inadvertent and prudent: "Now I see how it should have been done."
- Inadvertent and reckless: "What's a service boundary?"
Most teams underestimate the third and fourth categories — the debt accumulated through inexperience or evolving understanding — by an order of magnitude.
How to Measure Technical Debt
You cannot reduce what you do not measure. The challenge is that technical debt resists single-number quantification. The leaders I work with use a small portfolio of metrics, each catching a different signal.
1. Technical Debt Ratio (TDR)
The most cited quantitative metric. Tools like SonarQube calculate it as:
TDR = (Estimated remediation cost / Total development cost) × 100
A TDR under 5% is healthy. 5–10% is a yellow flag. Above 10% means debt is materially slowing your team. Treat the absolute number with skepticism — the trend matters more.
2. Code Churn
How often code is rewritten shortly after being committed. High churn in a specific module is one of the strongest leading indicators of hidden debt — engineers are circling the same code repeatedly because it resists clean changes.
3. PR Cycle Time in High-Debt Areas
Tag your codebase by module and track PR cycle time per area. Modules where PRs consistently take 3x longer than the median are debt hotspots. The pain shows up in human time before it shows up in any static analysis tool.
4. Change Failure Rate (CFR)
A DORA metric, but it doubles as a debt signal. When your CFR rises in specific services, you are looking at debt that has crossed from "annoying" into "actively breaking things."
5. Engineer Sentiment
The single most underused metric. Once a quarter, ask every engineer to rate, 1–10, how confident they are making changes in each major part of the codebase. Average the scores by area. Anywhere with a sub-6 average is debt — regardless of what your tooling says.
How to Prioritize Technical Debt
Once you can see the debt, the harder question begins: what do you actually fix?
The wrong answer — and the one most teams default to — is "the worst stuff first." This produces heroic rewrites that consume quarters and deliver no measurable business outcome.
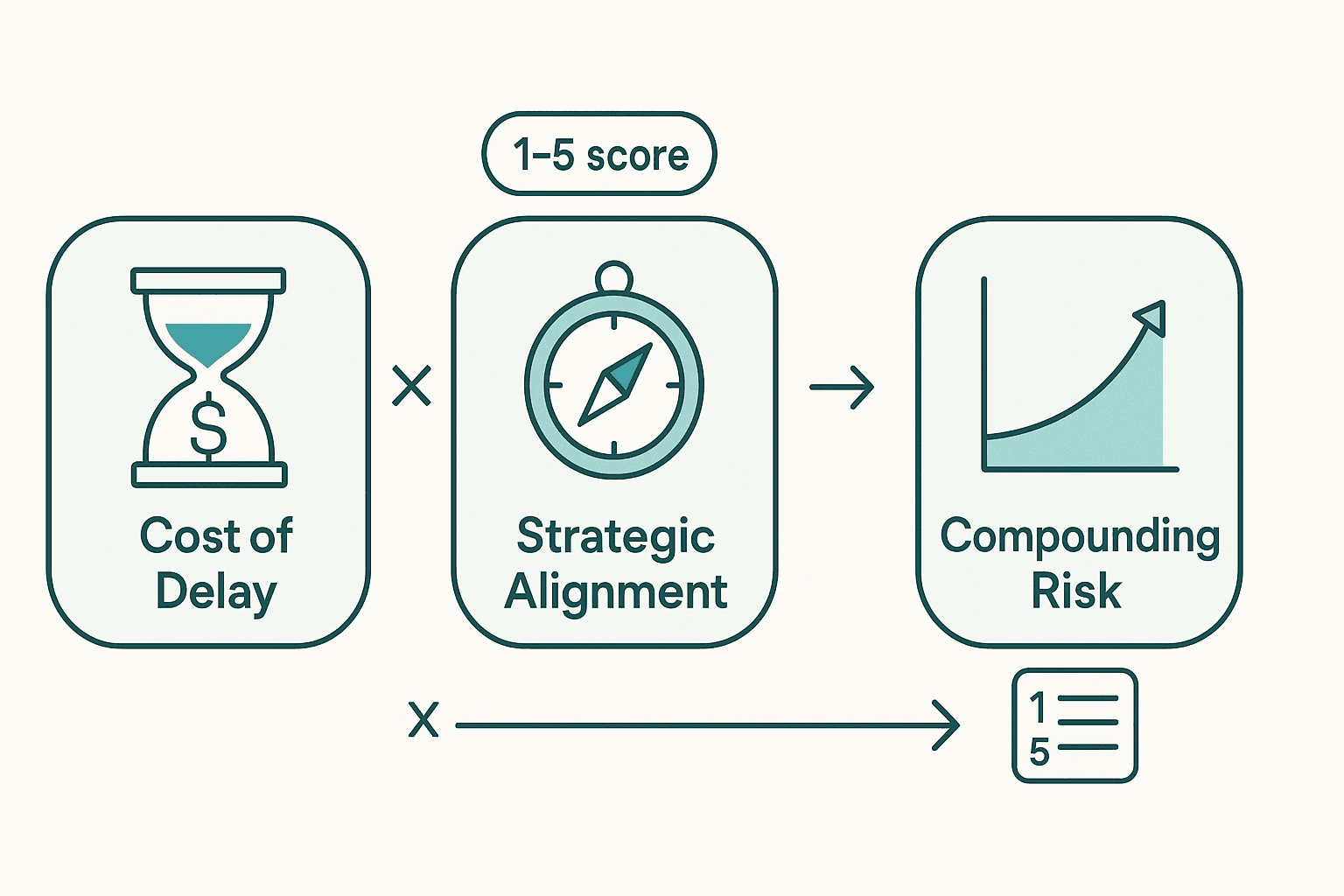
The right answer is to prioritize by leverage, not by ugliness. Three lenses I use, in order:
Lens 1: Cost of Delay
For each debt item, estimate what it costs you per month to not fix it. The cost shows up as:
- Slower feature delivery in that area (use cycle time data)
- Higher incident rate (use CFR and MTTR)
- Lost engineering capacity to onboarding pain
- Real revenue impact when debt blocks a deal
A debt item that costs you $30k/month in delayed feature throughput is more urgent than one that simply offends your sense of craftsmanship.
Lens 2: Strategic Alignment
Debt in a module that is about to be deprecated is not worth fixing. Debt in the module powering your next major launch is the highest-leverage thing your team can work on.
Map your debt inventory against your 12-month product roadmap. Anything in the path of upcoming work gets a priority bump. Anything in code likely to be retired drops to the bottom — or off the list entirely.
Lens 3: Compounding Risk
Some debt grows. A flaky test suite gets flakier as the codebase grows. A monolithic deployment pipeline gets slower with every team you add. A missing observability layer hides more bugs as traffic scales.
Compounding debt should be paid down earlier than its current pain suggests, because the cost curve is non-linear. Linear debt — a clunky internal admin tool no one touches — can sit at the back of the line forever.
A simple scoring rubric: rate each item 1–5 on cost of delay, strategic alignment, and compounding risk. Multiply the scores. Sort descending. The top of that list is your debt backlog for the next quarter.
How to Reduce Technical Debt Without Stopping Feature Work
This is where most debt reduction efforts collapse. Engineering proposes a "tech debt sprint." Product pushes back because the roadmap is full. Leadership picks a side. Nothing changes.
The patterns that actually work look different.
Pattern 1: The Fixed Allocation
Allocate a fixed percentage of every sprint — typically 15–25% — to debt reduction. Not "as much as we have time for." A guaranteed slice that ships every cycle.
The number that matters here is consistency, not size. Twenty percent every sprint compounds. Fifty percent once a quarter does not.
Pattern 2: The Boy Scout Rule, Codified
"Leave the code better than you found it" is a cliché until you back it with an explicit policy: every PR that touches a high-debt module must include at least one improvement in that module. Reviewers enforce it.
This works best for distributed, opportunistic debt — the kind that does not justify a dedicated initiative but accumulates everywhere.
Pattern 3: The Targeted Initiative
For debt that requires concentrated focus — a database migration, a framework upgrade, a service extraction — running it as a fixed-time, fixed-team initiative beats trying to wedge it into normal feature work.
The key constraints: a clear definition of done, a named owner who is accountable for delivery (not just "the team"), and a hard time box. Six weeks works for most initiatives. Anything over a quarter usually means the scope was wrong.
Pattern 4: The Replacement, Not the Refactor
Sometimes the right answer is not to repay the debt but to walk away from it. If a system is fundamentally misaligned with where the business is going, refactoring it is throwing good money after bad. Build the replacement, migrate, and delete.
This decision is one of the hardest a CTO makes — partly because it is irreversible, partly because the team that built the original system has emotional equity in it. But for genuinely misarchitected systems, replacement is often cheaper and faster than reform.
Communicating Technical Debt to the Business
Technical debt becomes a board-level conversation the moment it starts costing money. The vocabulary engineering uses ("legacy code," "spaghetti," "tech debt") does not translate. The vocabulary that does:
- Throughput cost: "Feature delivery in our payments domain is 40% slower than in our newer services."
- Risk exposure: "Our incident rate in checkout has tripled since Q3. Three of those incidents had revenue impact."
- Hiring drag: "New engineers take 6 weeks to ship in this codebase versus 2 weeks elsewhere."
- Revenue blockers: "We could not bid on the enterprise SSO contract because our auth system cannot support SAML in its current shape."
When you frame debt this way, you are no longer asking for permission to refactor. You are presenting an investment decision with a quantified return. That conversation happens at every other line item on the budget — engineering should not be the exception.
If you want a deeper view of the operating metrics that make this conversation concrete, the post on advanced engineering metrics walks through the numbers that translate engineering work into business language.
When to Bring in Outside Help
There are three moments when an outside perspective on technical debt pays for itself many times over:
- Pre-fundraise or pre-acquisition, when a technical due diligence review will happen anyway and you want to know what it will surface before someone else does.
- At the 15–50 engineer inflection point, when the debt accumulated as a small team becomes the bottleneck of a larger one — often a signal that engineering team scaling and architecture work need to happen together.
- Before a major architecture decision, when the cost of getting it wrong is high enough to justify a second opinion. This is the core of software architecture consulting.
The value of outside help is not the technical analysis. Most teams know roughly where their debt lives. The value is the political cover to make hard prioritization calls — and the experience of having seen what works (and what fails) across dozens of codebases.
Frequently Asked Questions
How much technical debt is normal?
Every codebase has debt. Healthy teams typically run a Technical Debt Ratio between 3–7%, with concentrations in older modules. The right amount of debt is the amount you can manage without it slowing your roadmap by more than 20%.
Should we ever do a "tech debt sprint"?
Occasionally — for concentrated, well-scoped initiatives that genuinely need focused attention. As a recurring habit, no. Sustained 15–25% allocation per sprint outperforms quarterly debt sprints by a wide margin because it prevents the rebound where debt reaccumulates faster than it gets paid.
How do I convince product leaders to invest in debt reduction?
Stop using the word "debt." Frame it in business outcomes: feature throughput, incident rate, hiring velocity, contract eligibility. Quantify the cost of delay. Product leaders are not against improving the system — they are against vague engineering asks they cannot evaluate.
What's the difference between technical debt and bad code?
Bad code is code that should never have been written that way given what was known at the time. Technical debt is code that was reasonable when written but has become suboptimal as the system or requirements evolved. The distinction matters because it changes the conversation: bad code is a quality problem, debt is a maintenance investment.
Is rewriting always a bad idea?
No. Rewriting gets a bad reputation because it is usually attempted for the wrong reasons (a new team disliking the old code) or under the wrong conditions (no clear scope, no time box, business demands continue unabated). When a system is fundamentally misaligned with current requirements and the cost of incremental fixes exceeds the cost of replacement, rewriting is the right call. The bar is just much higher than most teams assume.
How do I track technical debt across multiple teams?
Maintain a debt inventory at the org level — typically a structured backlog in your work management tool, with each item tagged by module, estimated effort, cost of delay, and strategic alignment. Review it quarterly with engineering leadership. Make debt reduction a line item in every team's quarterly goals, not an aspirational extra.
The Bottom Line
Technical debt is not a moral failing. It is a financial instrument — sometimes prudent, sometimes reckless, always something to be managed deliberately rather than emotionally.
The leaders who handle it well share three habits. They measure it continuously, not in panic. They prioritize by business leverage, not by what is most painful to look at. And they bake debt reduction into the operating cadence of their team, instead of treating it as something they will get to once feature pressure eases.
Feature pressure never eases. Debt either gets managed alongside the work, or it eventually becomes the work.
If you would like a second pair of eyes on your debt inventory, your prioritization model, or the architecture decisions driving future debt accumulation, get in touch. I work with engineering leaders to make these calls clearly and defensibly.
Hit like if you enjoyed this post!
Keep reading
Hosting Strategies for Web Apps: When to Use AWS
Discover the top three use cases where AWS (or similar cloud services) is the best choice for hosting web applications, focusing on scalability, global availability, and serverless architectures.
February 23, 2025ArchitectureWhen to Choose Monolith Over Microservices
Choosing between a monolith and microservices is a critical architectural decision. This article explores key scenarios where a monolithic architecture is the smarter choice, helping engineering leaders balance complexity, scalability, and operational efficiency.
February 04, 2025